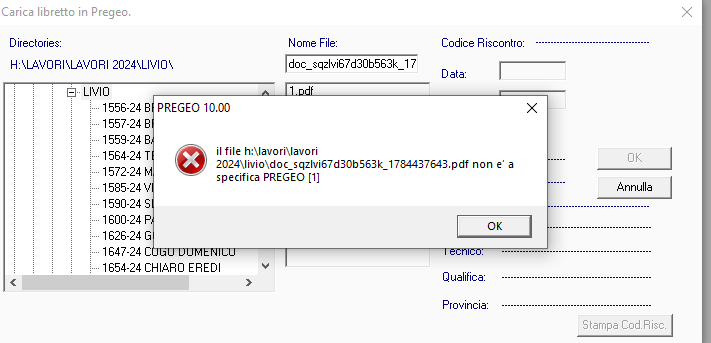
Qualcuno sa dirmi come mai mi compare questo errore nel caricamento del libretto pregeo ?
Poi ho provato anche a copiare dal pdf ma le barre di separazione dei dati non sono veritcali.
Avete una soluzione oppure un programma da consigliarmi ?
Grazie.
Perin Maurizio
DOC_SQZLVI67D30B563K_1784437643.pdf (33,2 KB)
Effettivamente il file è in un formato che non viene gestito dai diversi software e da diversi convertitori di libretti da pdf a dat o txt.
Secondo me sei costretto ad inserire a mano i dati.
Saluti
Prova a semplificare il nome del file.
niente da fare. ho rinominato ma mi viene questo errore.
ho cqm allegato il pdf se qualcuno vuole provare.
grazie.
DOC_SQZLVI67D30B563K_1784437643.pdf (33,2 KB)
Ho provato a caricarlo con diversi software, e a “trasformarlo” da pdf a dat con alcuni software ma niente da fare è un formato strano.
Ho visto che il libretto è stato rilasciato dall’Agenzia di Padova, chissa se è una anomalia singola oppure il sistema ha cambiato qualcosa nel rilascio dei libretti pregeo.
Il file è semplicemente criptato!
Come consiglia Fausto, dovrai inserire i dati manualmente su un Blocco Note.
Stessa cosa, concordo con i colleghi. Provato con software diverso, ma non funziona, a mio parere richiedi info al Catasto di Padova, o semplicemente copialo a mano.
Va bene. Inserirò i dati a mano
In che senso file criptato ?
Il file PDF riesco ad aprirlo con Adobe Acrobat Reader 2024.004.20272
Inoltre il testo è interamente selezionabile
Infine il file NON risulta conforme al formato PDF/A
Ma è capitato altre volte con file generato da DoCFa e PreGeo
Nonostante il sistema lo riteneva valido ma non valido da altri servizi on-line
| File |
DOC_SQZLVI67D30B563K_1784437643.pdf |
| Compliance |
pdfa-1b |
| Result |
Document does not conform to PDF/A. |
| Details |
Validating file “DOC_SQZLVI67D30B563K_1784437643.pdf” for conformance level pdfa-1b |
The separator before an ‘endobj’ must be an EOL.
The dictionary must not contain the key ‘Filter’.
The required XMP property ‘dc:title’ for the document information entry ‘Title’ is missing.
The required XMP property ‘dc:creator’ for the document information entry ‘Author’ is missing.
The required XMP property ‘xmp:CreatorTool’ for the document information entry ‘Creator’ is missing.
The XMP property ‘xmp:CreateDate’ is not synchronized with the document information entry ‘CreationDate’.
The XMP property ‘xmp:ModifyDate’ is not synchronized with the document information entry ‘ModDate’.
The XMP property ‘pdf:Producer’ is not synchronized with the document information entry ‘Producer’.
The separator before ‘endstream’ must be an EOL.
The separator before an ‘endobj’ must be an EOL.
A device-specific color space (DeviceRGB) without an appropriate output intent is used.
The embedded ICC profile’s version is not supported.
The document does not conform to the requested standard.
The file format (header, trailer, objects, xref, streams) is corrupted.
The document doesn’t conform to the PDF reference (missing required entries, wrong value types, etc.).
The document contains device-specific color spaces.
The document’s meta data is either missing or inconsistent or corrupt.
The document does not conform to the PDF/A-1b standard.
Done.|
A parte quanto sopra non conosco i difetti / limiti di PreGeo (uso DoCFa)
Nello specifico è consentito lo spazio vuoto dopo SPIGOLO FABBRICATO ?
Ciao Alberto.
Concordo che il file è selezionabile ma se provi ad incollarlo all’interno del libretto pregeo le linee di separazione tra i numeri vengo obblique e pertanto va modificato.
Maurizio.
In effetti risultano due font
Anonymous Pro Bold e Gentium Italic
entrambi con codifica CID Identity-H (sottoinsieme incorporato)
La suddetta codifica non è supportata da Libre Office
(incolla caratteri rettangolo)
In sostanza non sono caratteri ASCII
PDF24 Tools riesce a convertire in testo leggibile
ok. Provo.
Grazie e ti farò sapere.
niente. con copia incolla solo geroglifici
Controlla il file allegato e vedi cosa carica
199715514.dat (2,0 KB)
sarei curioso di sapere come hai fatto a convertirlo.
a me le stringhe verticali vengono obblique.
tipo così :
2/200/23.7820/513.592/CHIODO/
Inizialmente ho pensato a convertire il PDF originale con PDF OCR
Quando occorre lo faccio per risparmiare tempo a trascrivere il testo
Nella rete internet spesse volte trovo file PDF immagine (e non PDF testo)
Di norma il testo è quasi riprodotto alla perfezione (90-95% ?)
Occorre controllare e modificare dove occorre (a volte non trovo subito gli errori)
Modifiche singole oppure multiple con Modifica + Trova e sostituisci
Il problema è che si trascina dietro il font particolare
e poi non è possibile incollare il testo (leggibile) su Writer (LibreOffice)
Rimaneva un solo modo (non ho pensato altro)
Prima ho convertito il file PDF come immagine JPG poi ho ripetuto PDF OCR
In questo modo è possibile incollare il testo (font GlyphLess) su software Writer
Sono stati copiati i caratteri slash (barra obliqua) poi corretti velocemente
Ho notato altri errori sparsi (tipo il carattere lettera O con numero 0 zero)
Ho pensato a testare il file PDF generato con stampa virtuale
Non era necessario ma volevo provare il convertitore da seguente pagina web
https://www.geolive.org/pdf-to-dat.html
Il convertitore non riconosce come testo quel PDF con particolare font
Il PDF caricato non contiene le righe del libretto delle misure
Ritengo che in questi casi l’unica soluzione sia la copiatura a mano. Per controllare il corretto riconoscimento dei testi si perde molto più tempo e soprattutto è molto più facile che possa sfuggire qualche numero e commettere un errore di inserimento.
1 Mi Piace